MapReduce实现电影推荐
算法概述
算法的目标是,根据用户已经看过的电影来为用户合理推荐没有看过的电影。详细问题描述在这里 用hadoop构建电影推荐系统
算法输入格式
|
|
第一行中,“1”代表用户id;“101”代表电影id;“5.0”表示该用户看过这部电影,并评分为5.0。
算法输出格式
|
|
其中,以第一行为例,“1”代表用户id;“101”代表电影id;“44.0”表示该电影的综合推荐值,这个值越大表示这个电影越值得推荐。这里我们对数据集中的所有电影都进行综合评估,没有排除掉那些用户已经看过的电影,后续可能会继续完善一下。
算法流程
我们分五个步骤来完成这件事,每一个步骤都是一个mapreduce任务,在主函数中依次调用这五个任务。首先,给出主函数代码。
|
|
Step1
步骤一将处理成如下结构
|
|
以第一行为例,意义为:用户1看了101,102,103这三部电影,分别评分为5.0,3.0,2.5。至于如何得到这个结果,我先贴出map和reduce两个函数的源码。
|
|
map函数非常简单,将每一行用“,”切分成字符串数组后,以用户id为key,电影id和评分连接起来的新字符串作为值。
|
|
reduce函数以map的输出为输入,同样key值的map输出为同一个reduce group,所以reduce就是将key值相同的所有value拼接起来,也就有了上面的结果。
Step2
步骤二以Step1的输出为输入,得到如下结果:
|
|
以第2行为例,意义为:有三个用户既看了101电影又看了102电影。具体实现如下。
|
|
map函数针对每一行输入,进行切分,切分后用双重for循环对电影ID进行两两组合,并将组合结果作为key输出,value为1。
|
|
reduce函数很简单,其实就是一个按组计数的过程。
Step3
步骤三以Step1的输出为输入,生成如下文件
|
|
应该。。。不用。。。解释。。。能看出。。。是什么意思的吧。恩,就默认大家都能看懂了吧。直接上代码。
|
|
map以电影id为key,用户id:评分为值。
|
|
reduce就是将同一个key的value连接为一个字符串。
Step4
这个步骤的任务是把Step3和Step2的输出合并为一个文件,但是重点在于是将两个文件的相应行进行合并。合并结果应该是这样的
|
|
以第一行为例,意义就是:所有用户中有4个用户的既看了101电影又看了103电影,所有看了101电影的用户对它的评分如下。之所以处理成这样,是为了最后一步的矩阵计算做准备。
|
|
这个步骤的特殊之处在于它的输入是两种格式不同的文件,对它们要进行不同的处理,并且要将结果统一成key和value的形式再传给reduce。map函数中用if和else来分别处理两个文件,if处理的是Step2的输出,输出的key是文件的第一个字段,value是输入的这一行文件。else处理的是Step3的输出,将这个文件每一行按键值对的方式存放再全局字典中(Java的HashMap)。
|
|
reduce将key值相同的map输出和dit中对应的值连接起来。
Step5
这个步骤应该是最复杂的了。先上个图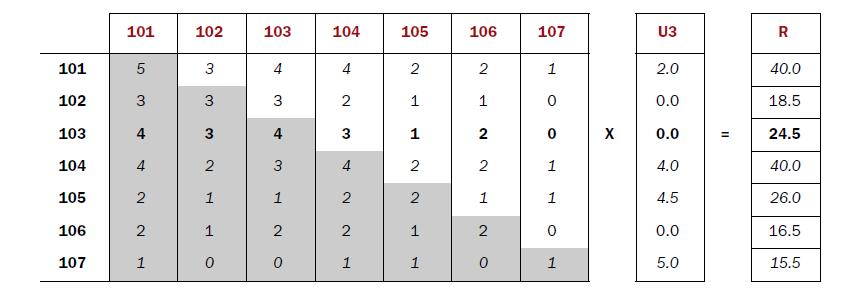
上面的图中,左边的矩阵中的每个数值表示所有用户中既看了该行对应的电影又看了该列对应的电影的用户数量,也就是Step2中我们的计算结果,右边的列向量表示用户3对每个电影的评分,等号右边就是对每个电影的推荐值。具体实现如下
|
|
map输出的key是用户id和当前评价的电影id,输出的值其实是当前评价的电影的推荐值的一部分。for循环是针对每一个用户计算,并不是针对每一个电影计算。
|
|
reduce将用户id和电影id都相同的值累加,最终输出最终结果。
